HPClab2
高性能计算 lab2
!!!
源代码可以参考这个仓库喔https://gitee.com/Wuhlan3/hpc
!!!
一、基于MPI点对点通信的矩阵乘法
基本思路
我们可以将矩阵B分配给所有的进程,并将矩阵A进行划分,将每一部分分配给对应的进程。在每个进程完成自己那一部分的计算之后,汇总到主进程,组合成最终目标矩阵C。
其中涉及到的主要的MPI函数包括:
- 初始化、获取进程数目与当前进程号
1 | |
- 路障函数,用于同步
1 | |
- 点对点通信函数
1 | |
- MPI获取时间的函数
1 | |
- MPI的释放
1 | |
详情可以参考文件中的源码mpi_matrix_mul1.cpp
编译与运行
1 | |
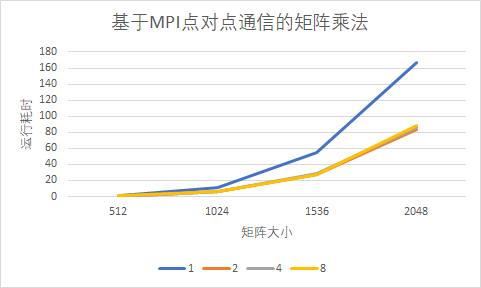
运行结果
| 核数 | 512 | 1024 | 1536 | 2048 |
|---|---|---|---|---|
| 1 | 0.810431 | 11.400184 | 54.643829 | 166.500494 |
| 2 | 0.503364 | 5.933909 | 27.939495 | 83.671942 |
| 4 | 0.608522 | 6.119340 | 28.566730 | 85.674031 |
| 8 | 0.675070 | 6.000397 | 27.530209 | 87.848682 |
二、基于MPI集合通信的矩阵乘法
基本思路
基本流程同一类似。只不过改用集合通信函数,可以更加方便地进行进程间的通信,而不需要使用for循环、关注进程的编号等等。集合通信函数可以自行划分内存块。感觉用到类型派生的函数的话反而变得更加麻烦,所以在另一个文件中使用了一下,权当练习练习,可以查看文件mpi_matrix_mul3.cpp。
其中涉及到的主要的MPI函数包括:
- 广播函数,用于将B矩阵发给所有进程
1 | |
- 散射函数,将A矩阵划分,发给对应的进程
1 | |
- 聚集函数,收集所有计算好的C矩阵,组合成完整的C矩阵
1 | |
详情可以参考文件中的源码mpi_matrix_mul2.cpp
编译与运行
1 | |
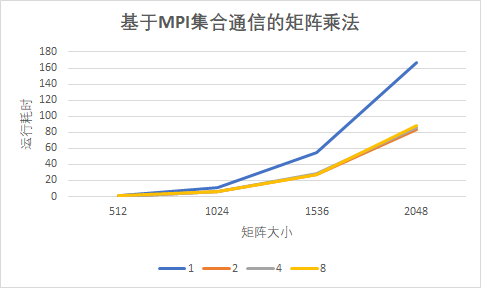
运行结果
| 核数 | 512 | 1024 | 1536 | 2048 |
|---|---|---|---|---|
| 1 | 0.914887 | 15.457199 | 89.563702 | 232.458000 |
| 2 | 0.555392 | 9.096576 | 51.484947 | 134.997501 |
| 4 | 0.502040 | 9.375724 | 51.218516 | 149.110322 |
| 8 | 0.617615 | 11.616788 | 51.633731 | 140.564852 |
两种通信方式的比较
可以很明显地看到,集合通信方式比点对点通信方式慢上许多,集合通信的运行时长多了接近一倍。这貌似与预先设想的不太一样。具体原因可能在于,在进行点对点通信的时候,我也对矩阵进行了手动的平均划分,而集合通信的过程很可能需要函数内部进行自己判断如何平均划分。所以虽然集合通信写起来更加方便,但性能比不上点对点的通信方式。
三、定义自己的MPI类型
基本步骤
定义一个结构体
1
2
3
4
5typedef struct
{
double A[SIZE][SIZE];
double B[SIZE][SIZE];
} AandB;使用MPI_Type_create_struct函数
1
2
3
4
5
6
7
8
9
10
11int count = 2;//块数
int blocklengths[count] = {m * n, n * k};//每个块的长度
MPI_Aint offsets[count];//块偏移量
MPI_Get_address(aandb.A, &offsets[0]);
MPI_Get_address(aandb.B, &offsets[1]);
offsets[1] = offsets[1] - offsets[0];
offsets[0] = 0;
MPI_Datatype types[count] = {MPI_DOUBLE, MPI_DOUBLE};//块类型
MPI_Datatype aandbtype;//自定义MPI类型
MPI_Type_create_struct(count, blocklengths, offsets, types, &aandbtype);//创造属于自己的类型
MPI_Type_commit(&aandbtype);//提交,使得该类型可以被使用在集合通信中的使用。发送给所有进程
1
MPI_Bcast(&aandb, 1, aandbtype, 0, MPI_COMM_WORLD);
详情可以参考文件中的源码mpi_matrix_mul3.cpp
编译与运行

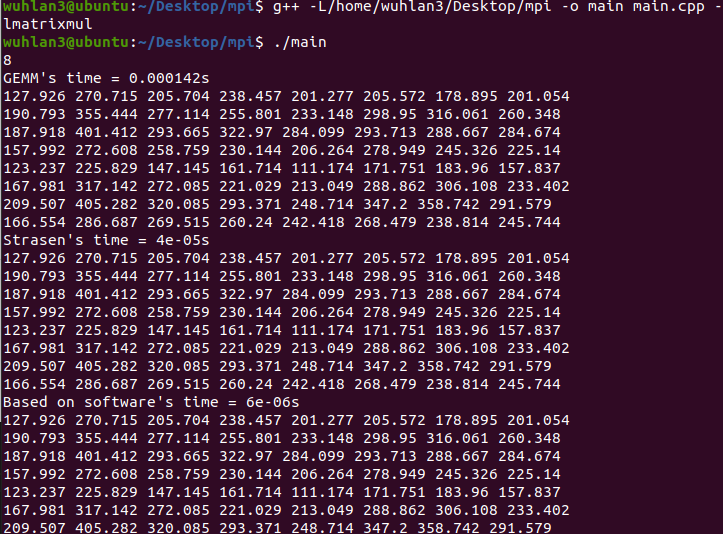
结果正确。
四、改造Lab1成矩阵乘法库函数
动态链接库
动态链接库提供了Lab1中三种矩阵的乘法函数:
1 | |
逐步编译与链接
1 | |
makefile文件
1 | |
使用后生成.so文件:

编译main文件可以正常运行:
遇到的问题
1.内存不足
对于点对点通信,一开始我使用的是一维数组存储矩阵的方式,我想着一维数组寻址会更加方便,使用MPI_Send()和MPI_Recv()函数时也会更加方便。小于512的矩阵还是能够正常计算的,但是当大小足够大时就会出现报错了。这是因为double A[1024*1024]这样的数组很可能已经超过了数组的上限(其中double是8字节的)。
只好改成二维数组的方式来存储。但是静态分配内存还是会出现segment
fault的错误。最终只能使用动态分配内存。
此外,我还发现在mpi中使用malloc很容易出现错误,实在搞不明白具体原因。在经过大半天的调试后仍然失败。最后使用c++中的new和delete组合,就成功了。
2.编译遇到的问题
在linux上编译可能需要添加oversubscribe
3.二维矩阵在集合通信函数中的使用
1 | |
比如说,假设A矩阵有8行,有4个进程。那么这种写法,是能够将其中的每两行分配个对应的进程的。